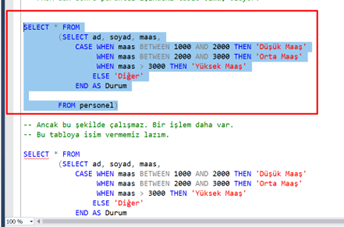
Merhaba arkadaşlar,
Bugün, veri tabanı tasarımının
olmazsa olmazı, belki de en çok kafa karıştırdığı düşünülen ama aslında hayat kurtaran konusuna,
Normalizasyon‘a derin bir dalış yapacağız arkadaşlar.
Amacımız, bu soyut gibi görünen kuralları,
somut örneklerle adım adım çözümlemeye çalışacağız. Hazırsanız başlayalım!
İlişkisel Veri Tabanı nedir?
Bir önceki videoda, bir veritabanının düzenli bir bilgi deposu olduğundan bahsetmiştik.
Peki, kelimenin başında geçen ‘
İlişkisel’ ifadesi nereden geliyor? Cevabı,
tabloların birbiriyle olan bağlantısında yatıyor arkadaşlar
Öncelikle Veritabanındaki tabloları ve bunun ilişkilerini anlatmak için Excel’den örnek vermek istiyorum. Excel bize ilişkisel veritabanının
temel yapı taşlarını anlatır. Şöyle ki;

- Excel’deki bir çalışma sayfası, veritabanındaki bir tabloya karşılık gelir arkadaşlar.
Gördüğünüz gibi birçok Excel Sayfası var. Eğer Veritabanı olsaydı her biri birer tablo olduğunu düşünebilirsiniz.

- Excel’deki bir satır, veritabanında bir kaydı temsil eder (örneğin, tek bir müşteriye ait tüm bilgiler). Adres, Ad Soyad, telefon gibi

- Excel’deki sütunlar ise, veritabanında bir alanı tanımlar arkadaşlar (her bir alana veri tabanında biz attribute diyoruz)
(örneğin, tüm müşterilerin ‘İsim’ bilgisinin saklandığı yer diyebiliriz)
Veri Tabanı yapısını Excel’den örnekledik.
Peki Excel ile Veritabanı arasındaki kritik fark Nedir?
Excel’de genelde tüm veriyi
tek bir sayfada tutmaya çalışırız. Bize daha kolay gelir. Öyle alıştık çünkü
Oysa ilişkisel veri tabanının gücü, bu veriyi
mantıklı, küçük tablolara bölüp, sonra bu tabloları birbirine
akıllıca bağlamakta yatar.
Bu bağlantılar sayesinde hem veri tekrarının önüne geçeriz, hem de verimliliği ve doğruluğu artırmış oluruz.
Peki Neden Normalizasyon?
Tam da bu noktada şöyle bir soru aklımıza gelmeli:
“Madem Excel’deki gibi tek bir tabloda tutabiliyoruz, neden uğraşıp veriyi parçalara ayıralım ki?”
Bu, çok yerinde bir soru. Hemen bu sorunun cevabını
somut bir örnekle birlikte verelim.
Giyim Mağazası Örneği ile Normalizasyon
[EXCEL AÇ : “Tablo Yapım Aşaması 1” Sayfasına Geç]
Diyelim ki bir giyim mağazası için bir sipariş takip sistemi tasarlıyoruz. İlk aklımıza gelenler:
- Sipariş verilen Ürün nedir? / Ürün Adı
- Sipariş verilen ürünün tutarı? / Sipariş Tutarı
- Siparişi veren Müşteri Kim? / Müşteri Adı
- Siparişin Verildiği Tarih Nedir? / Sipariş Tarihi
- Siparişin Ödeme yöntemi Nedir? / Ödeme yöntemi (Visa, mı, Nakit mi?)
- Siparişin gideceği adres neresi?/ Teslimat Adresi

Sorulara cevap verdiğimizde Tablo başlıklarımız bu şekilde mantıklı görünüyor.

Hadi bu tabloyu biraz veriyle dolduralım. Sizin için verileri ben bu şekilde doldurdum.

Tabloda tekrar eden verileri renklendiriyorum.
İşte! Tam da burada anlatmak istediğim
sorunu görüyoruz Arkadaşlar.
Bakın neler oluyor:
- “Ahmet Ltd. Şti.” ismi neredeyse her siparişte tekrar ediyor.
- “Kaban” ürünü defalarca satıldığı için sürekli tekrar ediyor.
- “Kredi Kartı” ödeme yöntemi aynı şekilde onlarca yerde yazılı.
Bu verileri tekrar etse ne olur? Bir zararı var mı? Bunu Şöyle Açıklayım
“Ahmet Ltd. Şti.” binlerce sipariş vermiş olsun. Bir gün bize gelip,
“Şirketimizin ismi artık Ahmet Tekstil A.Ş. oldu, lütfen tüm kayıtlarımızı günceller misiniz?” dedi.
Ne yapacağız?
Tablomuzda
binlerce satırı tek tek bulup, elle değiştirmemiz gerekecek! Bu:
- İnanılmaz bir zaman kaybıdır.
- Hata riski çok yüksektir. Bir satırı unutma ihtimaliniz var.
- Canlı bir sistemde bu kadar çok satırı güncellemek, performansı düşürür, hatta sistemi kilitleyebilir.
Ayrıca, aynı bilgi defalarca kaydedildiği için
depolama alanı israfı da cabası.
İşte Normalizasyon tam da bu kaosu önlemek için var! Arkadaşlar.
Normalizasyonun İki temel hedefi vardır:
- Veri tekrarını engellemek,
- Veri bütünlüğünü korumak.
Yani, Normalizasyon bize
“Dur, bu veriyi buraya bu şekilde yazma, şu şekilde ayır, daha temiz ve güvenli olur!” diyen bir kılavuzdur arkadaşlar.
Normalizasyon İşlemi Aşamaları
O zaman bu veriyi ayrı ayrı, küçük tablolara taşıyıp sonra da bu tabloları birbirine bağlayalım arkadaşlar.
Yani Normalizasyon işlemi yapalım.

Müşteri bilgileri için bir
Müşterilertablosu oluşturuyoruz. Her Müşteriye bir Numara atayalım

Ürün bilgileri için bir
Ürünler tablosu,

Ödeme yöntemleri için bir
Ödeme Yöntemleritablosu oluşturuyoruz.

Ana Siparişler tablosunda ise artık;
Müşteri adı yazmak yerine, MüşteriID yazıp karşılık gelen numarasını yazıyoruz.
Ürün adı yazmak yerine ÜrünID yazıyoruz.
Artık “Ahmet Tekstil”in ismini değiştirmek için Müşteriler tablosundaki
tek bir satırı güncellememiz yeterli oluyor!
İnanılmaz değil mi?
Peki Bu çizgilerle gösterdiğim, Tablolar Nasıl Birbirine Bağlanıyor?
(Ses tonunuzu hafifçe değiştirerek, bir sonraki mantık adımını işaret edin)
MüşteriID: 1 yazdığımızda, veritabanı nasıl oluyor da bunun ‘Ahmet Bey’ olduğunu anlıyor?
İşte ilişkisel veri tabanının sihri ve ‘ilişkisel’ kelimesinin veritabanındaki karşılığı
İkincil Anahtar ya da İngilizce adıyla
Foreign Key ile tabloları birbirine bağlıyoruz.

Şu an ekranda gördüğünüz, Siparişler tablomuzdaki MüşteriID aslında bir referanstır.
Buradaki ‘3’ rakamı, ‘Ahmet Bey’in kimlik kartı numarası gibi.
Siparişi Veren 3 Numarayı Alıp, Müşteriler tablosuna gittiğinde, birebir o numarayı buluyoruz ve ‘Ahmet Bey’in tüm bilgilerine bu sayede ulaşabiliyoruz.
Excel’de DÜŞEYARA Bilenler durumu kavrayacaktır.
İşte ilişkisel veri tabanınındaki bu işlemi İkincil Anahtar, yani Foreign Key dediğimiz kavram yapıyor.
Bu bağ, sadece bir bağlantı değil, aynı zamanda bir
güvenlik mühendisidir. Veri bütünlüğünü otomatik olarak sağlar.
Örnek verecek olursak;
Siparişler tablosunda siparişi olan bir müşteriyi (örneğin ID’si 3 olan Ahmet Bey’i) Müşteriler tablosundan silmeye kalktığınızda, veri tabanı size izin vermez. Sizi uyarır:
“Dur! Bu müşteriye ait aktif siparişler var. Önce onları silmelisin.” der
Ya da Ürünler tablosunda olmayan bir ÜrünID (mesela 999) ile yeni bir sipariş girmeye çalıştığınızda, veri tabanı yine reddedecektir:
“Böyle bir ürün yok, lütfen geçerli bir ürün kodu girin.” Der size.
Günlük Hayattan Bir Örnek: Banka
Peki, bu Foreign Key kavramını günlük hayatta nerede görüyoruz? Aslında her yerde! Varlar.
Bu sefer’de size çok tanıdık gelecek bir örnekle anlatayım:
Banka.

Düşünün, Örneğin Ziraat Bankasına gidip yeni bir hesap açtırdınız. Banka size hemen
benzersiz hiçbir müşterisinde olmayan bir müşteri numarası verir.
İşte bu numara, bankanın devasa veri tabanının Müşteriler
tablosundaki (Birincil Anahtarınız) yani Primary Key olarak sizin adınıza bir kayıt açılır.

Bu Tablomuzda Primary Keyiniz Müşteri No’dur.
ilaveten adınız, soyadınız, adresiniz, anne kızlık soyadınız gibi sadece sizi ilgilendiren sabit bilgileriniz tutulur.

Şimdi, Ziraat Bankasında bir işlem yaptığınızı hayal edin.
ATM’den Para çekiyorsunuz, İnternet Bankacılığından havale yapıyorsunuz veya fatura ödüyorsunuz.
Banka, bu işlemi kaydederken, Banka İşlemleri veya Hesaplar gibi bir tabloya şunları yazar:
‘Şu tarihte, şu ATM’den, 500 TL çekilmiştir.’
Ama asla bu kaydın içine sizin
adınızı ve soyadınızı tekrar tekrar yazmaz! Yapacağı şey çok basittir.

Görselde gördüğünüz gibi O kaydın ‘MüşteriID’ sütununa
sizin o benzersiz müşteri numaranızı (yani 1234567’i) yazar. Karşılığında da Banka İşlemlerinde 1234567’ye karşılık gelen kayıtlar size ait işlemlerdir.
İşte Banka İşlemleri Tablosundaki yazan 1234567 kaydı bir
Foreign Key yani İkincil Anahtardır. ‘dir.
Banka, Mustafa Bey 500 TL çekti’ raporunu oluşturmak istediğinde, Banka İşlemleri tablosundaki MüşteriID’yi alır, Müşteriler tablosundaki ID ile birleştirir (JOIN işlemi yapar) ve işlemi yapan kişinin siz olduğunu anlar.
Excel’de Düşeyara bilenler ne demek istediğimi anlayacaklardır.

Yani,
Primary Key (Müşteri Numaranız) sizi tanıtken, Foreign Key ile yaptığınız tüm işlemleri fiziksel bir bağ gibi birbirine bağlıyor.
Primary Key Benzersiz kayıtlara verilir. Foreign Key ise benzersiz kayıtlarla bağ kuran yapı diyebiliriz.
İşte veri tabanı ilişkilerinin büyüsü ve mantığı tam olarak budur.
Peki, Bu Kadar Mükemmel Bir Sistemin Hiç Mi Eksisi Yok?
Maalesef var arkadaşlar, her güzel şeyin bir de bedeli vardır.
Normalizasyon dediğimiz kavram,
veri tutarlılığı ve güvenliği için bir mükemmel olsa da,
bu avantajın bir karşılığı var o da :
Sorgu Performansı Düşüklüğü. Arkadaşlar.

Şimdi şu görsele bir bakın. Ne kadar çok tablo, ne kadar çok ilişki varsa, bir rapor almak için o kadar çok JOIN işlemi yapmamız işlemi yapmamız gerekiyor.
Tekar hatırlatıyım JOIN Excel’deki DÜŞEYARA gibidir. Onlarda Tablodaki verileri DÜŞEYARA ile çağırdığınızı düşünün
Bu da veritabanı için ekstra iş yükü demek ve
raporlama için yapacağınız sorguları yavaşlayacaktır.
Yani, normalize edilmiş bir yapı,
güncelleme için hızlıdır, ama sorgulama için nispeten yavaştır.
Peki Bu Sorunla Nasıl Başa Çıkıyoruz? Pratik Çözüm Ne?
Pratikte bu durumun çok akıllıca bir çözümü var:
İki sistemli (Hybrid) yaklaşımdır.
1. OLTP (İşlemsel) Veritabanı:
Günlük işlemlerinizi yaptığınız, Normalizasyon kurallarına uygun tasarlanmış sistemdir.
Sipariş girme, müşteri güncelleme gibi işlemler burada,
hızlı ve güvenli bir şekilde yapılır.
2. OLAP (Analitik) Veri Ambarı:
Raporlama ve analiz için kullanılan,
bilerek (Normalizasyonun Tersi)
denormalize edilmiş yapıdır.
Her gün işlenen veriler, sistemin az kullanıldığı saatlerde (genellikle gece olur) buraya aktarılır ve raporlamayı hızlandırmak için tekrar içeren geniş, yassı tablolar halinde saklanır.
Yani,
hem güvenli işlem yaparız, hem de hızlı rapor almış oluruz.
Böylece her iki sisteminde en iyi yanlarını bir arada kullanmış oluyoruz.
Sonuç
Özetle arkadaşlar,
- Normalizasyon, veri tekrarını önleyerek bize tutarlılık, güvenlik ve esneklik sağlar.
- Foreign Key ise bu yapıyı bir arada tutan, ilişkileri güvence altına alan çimento görevi görür.
Bu temel prensipleri özümsediğinizde, ister bir e-ticaret sitesi, ister bir banka sistemi tasarlayın,
her veri tabanını çok daha sağlam kurgulayabilirsiniz arkadaşlar.
Bir sonraki videoda görüşmek üzere, kendinize iyi bakın